08基础篇-栈:如何实现浏览器的前进和后退功能?
浏览器的前进、后退功能,我想你肯定很熟悉吧?
当你依次访问完一串页面a-b-c之后,点击浏览器的后退按钮,就可以查看之前浏览过的页面b和a。当你后退到页面a,点击前进按钮,就可以重新查看页面b和c。但是,如果你后退到页面b后,点击了新的页面d,那就无法再通过前进、后退功能查看页面c了。
假设你是Chrome浏览器的开发工程师,你会如何实现这个功能呢?
这就要用到我们今天要讲的“栈”这种数据结构。带着这个问题,我们来学习今天的内容。
浏览器的前进、后退功能,我想你肯定很熟悉吧?
当你依次访问完一串页面a-b-c之后,点击浏览器的后退按钮,就可以查看之前浏览过的页面b和a。当你后退到页面a,点击前进按钮,就可以重新查看页面b和c。但是,如果你后退到页面b后,点击了新的页面d,那就无法再通过前进、后退功能查看页面c了。
假设你是Chrome浏览器的开发工程师,你会如何实现这个功能呢?
这就要用到我们今天要讲的“栈”这种数据结构。带着这个问题,我们来学习今天的内容。
上一节我讲了链表相关的基础知识。学完之后,我看到有人留言说,基础知识我都掌握了,但是写链表代码还是很费劲。哈哈,的确是这样的!
想要写好链表代码并不是容易的事儿,尤其是那些复杂的链表操作,比如链表反转、有序链表合并等,写的时候非常容易出错。从我上百场面试的经验来看,能把“链表反转”这几行代码写对的人不足10%。
为什么链表代码这么难写?究竟怎样才能比较轻松地写出正确的链表代码呢?
只要愿意投入时间,我觉得大多数人都是可以学会的。比如说,如果你真的能花上一个周末或者一整天的时间,就去写链表反转这一个代码,多写几遍,一直练到能毫不费力地写出Bug free的代码。这个坎还会很难跨吗?
当然,自己有决心并且付出精力是成功的先决条件,除此之外,我们还需要一些方法和技巧。我根据自己的学习经历和工作经验,总结了几个写链表代码技巧。如果你能熟练掌握这几个技巧,加上你的主动和坚持,轻松拿下链表代码完全没有问题。
事实上,看懂链表的结构并不是很难,但是一旦把它和指针混在一起,就很容易让人摸不着头脑。所以,要想写对链表代码,首先就要理解好指针。
我们知道,有些语言有“指针”的概念,比如C语言;有些语言没有指针,取而代之的是“引用”,比如Java、Python。不管是“指针”还是“引用”,实际上,它们的意思都是一样的,都是存储所指对象的内存地址。
接下来,我会拿C语言中的“指针”来讲解,如果你用的是Java或者其他没有指针的语言也没关系,你把它理解成“引用”就可以了。
实际上,对于指针的理解,你只需要记住下面这句话就可以了:
将某个变量赋值给指针,实际上就是将这个变量的地址赋值给指针,或者反过来说,指针中存储了这个变量的内存地址,指向了这个变量,通过指针就能找到这个变量。
这句话听起来还挺拗口的,你可以先记住。我们回到链表代码的编写过程中,我来慢慢给你解释。
在编写链表代码的时候,我们经常会有这样的代码:p->next=q。这行代码是说,p结点中的next指针存储了q结点的内存地址。
还有一个更复杂的,也是我们写链表代码经常会用到的:p->next=p->next->next。这行代码表示,p结点的next指针存储了p结点的下下一个结点的内存地址。
掌握了指针或引用的概念,你应该可以很轻松地看懂链表代码。恭喜你,已经离写出链表代码近了一步!
不知道你有没有这样的感觉,写链表代码的时候,指针指来指去,一会儿就不知道指到哪里了。所以,我们在写的时候,一定注意不要弄丢了指针。
指针往往都是怎么弄丢的呢?我拿单链表的插入操作为例来给你分析一下。
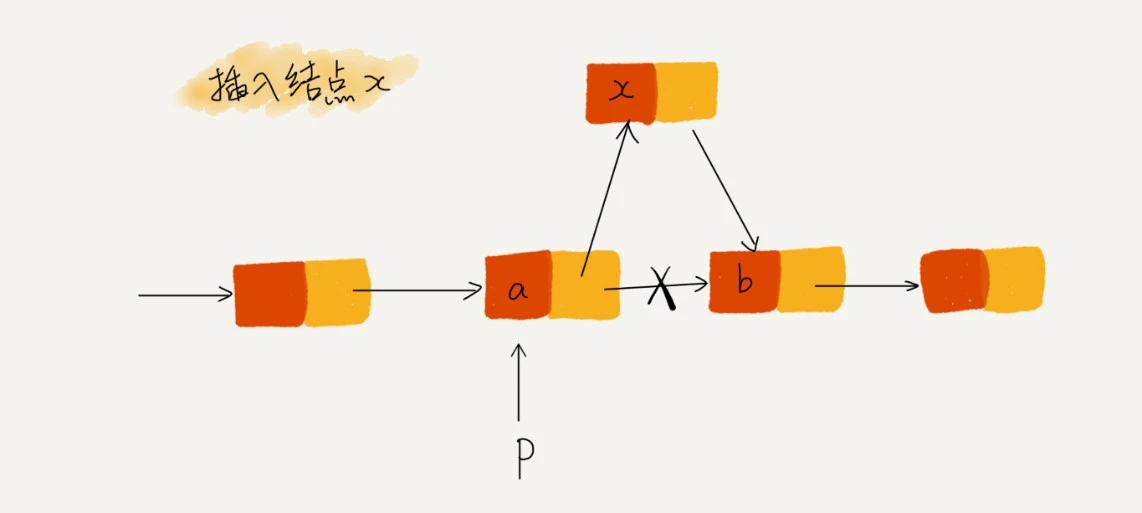
如图所示,我们希望在结点a和相邻的结点b之间插入结点x,假设当前指针p指向结点a。如果我们将代码实现变成下面这个样子,就会发生指针丢失和内存泄露。
1 | p->next = x; // 将p的next指针指向x结点; |
初学者经常会在这儿犯错。p->next指针在完成第一步操作之后,已经不再指向结点b了,而是指向结点x。第2行代码相当于将x赋值给x->next,自己指向自己。因此,整个链表也就断成了两半,从结点b往后的所有结点都无法访问到了。
对于有些语言来说,比如C语言,内存管理是由程序员负责的,如果没有手动释放结点对应的内存空间,就会产生内存泄露。所以,我们插入结点时,一定要注意操作的顺序,要先将结点x的next指针指向结点b,再把结点a的next指针指向结点x,这样才不会丢失指针,导致内存泄漏。所以,对于刚刚的插入代码,我们只需要把第1行和第2行代码的顺序颠倒一下就可以了。
同理,删除链表结点时,也一定要记得手动释放内存空间,否则,也会出现内存泄漏的问题。当然,对于像Java这种虚拟机自动管理内存的编程语言来说,就不需要考虑这么多了。
首先,我们先来回顾一下单链表的插入和删除操作。如果我们在结点p后面插入一个新的结点,只需要下面两行代码就可以搞定。
1 | new_node->next = p->next; |
但是,当我们要向一个空链表中插入第一个结点,刚刚的逻辑就不能用了。我们需要进行下面这样的特殊处理,其中head表示链表的头结点。所以,从这段代码,我们可以发现,对于单链表的插入操作,第一个结点和其他结点的插入逻辑是不一样的。
1 | if (head == null) { |
我们再来看单链表结点删除操作。如果要删除结点p的后继结点,我们只需要一行代码就可以搞定。
1 | p->next = p->next->next; |
但是,如果我们要删除链表中的最后一个结点,前面的删除代码就不work了。跟插入类似,我们也需要对于这种情况特殊处理。写成代码是这样子的:
1 | if (head->next == null) { |
从前面的一步一步分析,我们可以看出,针对链表的插入、删除操作,需要对插入第一个结点和删除最后一个结点的情况进行特殊处理。这样代码实现起来就会很繁琐,不简洁,而且也容易因为考虑不全而出错。如何来解决这个问题呢?
技巧三中提到的哨兵就要登场了。哨兵,解决的是国家之间的边界问题。同理,这里说的哨兵也是解决“边界问题”的,不直接参与业务逻辑。
还记得如何表示一个空链表吗?head=null表示链表中没有结点了。其中head表示头结点指针,指向链表中的第一个结点。
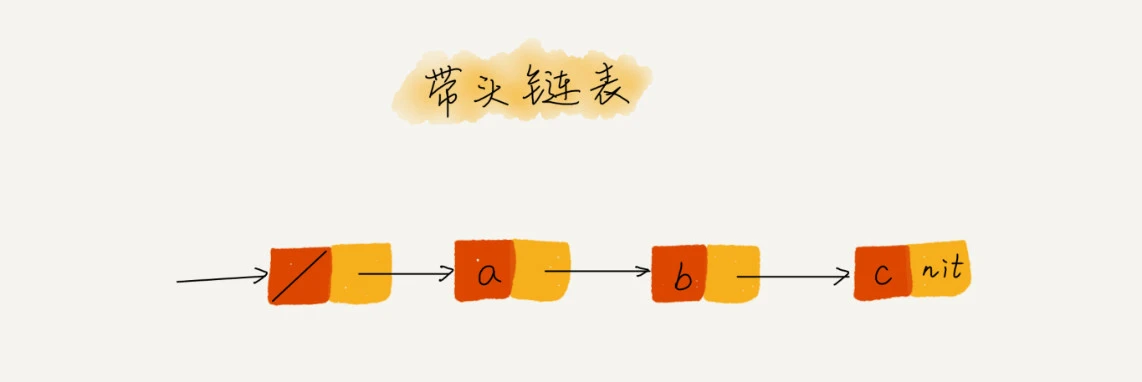
如果我们引入哨兵结点,在任何时候,不管链表是不是空,head指针都会一直指向这个哨兵结点。我们也把这种有哨兵结点的链表叫带头链表。相反,没有哨兵结点的链表就叫作不带头链表。
我画了一个带头链表,你可以发现,哨兵结点是不存储数据的。因为哨兵结点一直存在,所以插入第一个结点和插入其他结点,删除最后一个结点和删除其他结点,都可以统一为相同的代码实现逻辑了。
实际上,这种利用哨兵简化编程难度的技巧,在很多代码实现中都有用到,比如插入排序、归并排序、动态规划等。这些内容我们后面才会讲,现在为了让你感受更深,我再举一个非常简单的例子。代码我是用C语言实现的,不涉及语言方面的高级语法,很容易看懂,你可以类比到你熟悉的语言。
代码一:
1 | // 在数组a中,查找key,返回key所在的位置 |
代码二:
1 | // 在数组a中,查找key,返回key所在的位置 |
对比两段代码,在字符串a很长的时候,比如几万、几十万,你觉得哪段代码运行得更快点呢?答案是代码二,因为两段代码中执行次数最多就是while循环那一部分。第二段代码中,我们通过一个哨兵a[n-1] = key,成功省掉了一个比较语句i<n,不要小看这一条语句,当累积执行万次、几十万次时,累积的时间就很明显了。
当然,这只是为了举例说明哨兵的作用,你写代码的时候千万不要写第二段那样的代码,因为可读性太差了。大部分情况下,我们并不需要如此追求极致的性能。
软件开发中,代码在一些边界或者异常情况下,最容易产生Bug。链表代码也不例外。要实现没有Bug的链表代码,一定要在编写的过程中以及编写完成之后,检查边界条件是否考虑全面,以及代码在边界条件下是否能正确运行。
我经常用来检查链表代码是否正确的边界条件有这样几个:
当你写完链表代码之后,除了看下你写的代码在正常的情况下能否工作,还要看下在上面我列举的几个边界条件下,代码仍然能否正确工作。如果这些边界条件下都没有问题,那基本上可以认为没有问题了。
当然,边界条件不止我列举的那些。针对不同的场景,可能还有特定的边界条件,这个需要你自己去思考,不过套路都是一样的。
实际上,不光光是写链表代码,你在写任何代码时,也千万不要只是实现业务正常情况下的功能就好了,一定要多想想,你的代码在运行的时候,可能会遇到哪些边界情况或者异常情况。遇到了应该如何应对,这样写出来的代码才够健壮!
对于稍微复杂的链表操作,比如前面我们提到的单链表反转,指针一会儿指这,一会儿指那,一会儿就被绕晕了。总感觉脑容量不够,想不清楚。所以这个时候就要使用大招了,举例法和画图法。
你可以找一个具体的例子,把它画在纸上,释放一些脑容量,留更多的给逻辑思考,这样就会感觉到思路清晰很多。比如往单链表中插入一个数据这样一个操作,我一般都是把各种情况都举一个例子,画出插入前和插入后的链表变化,如图所示:
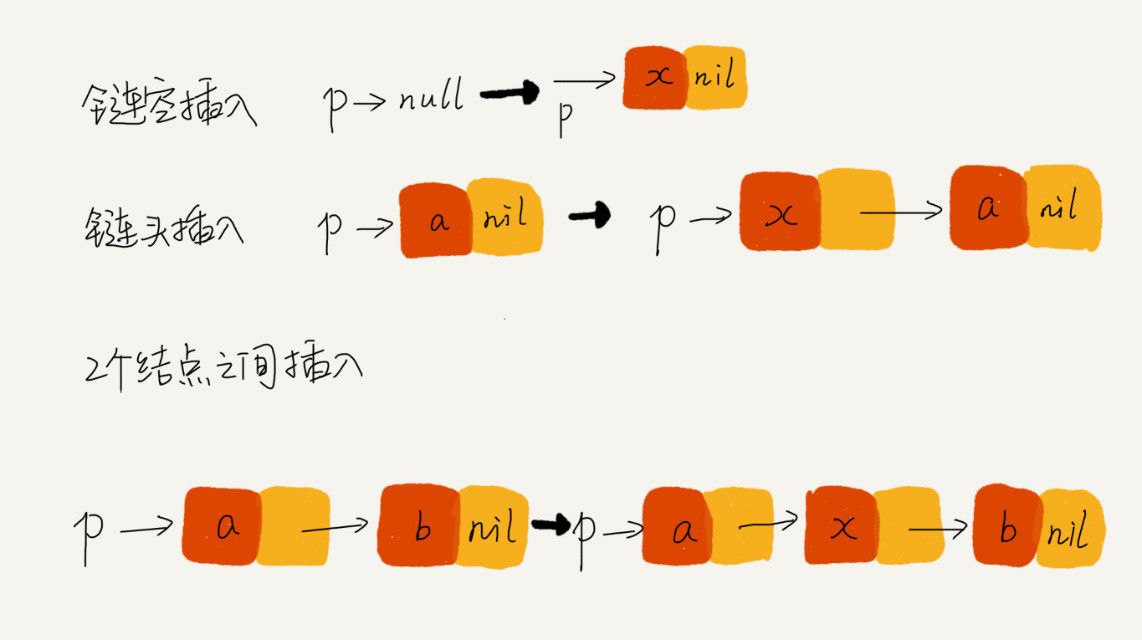
看图写代码,是不是就简单多啦?而且,当我们写完代码之后,也可以举几个例子,画在纸上,照着代码走一遍,很容易就能发现代码中的Bug。
如果你已经理解并掌握了我前面所讲的方法,但是手写链表代码还是会出现各种各样的错误,也不要着急。因为我最开始学的时候,这种状况也持续了一段时间。
现在我写这些代码,简直就和“玩儿”一样,其实也没有什么技巧,就是把常见的链表操作都自己多写几遍,出问题就一点一点调试,熟能生巧!
所以,我精选了5个常见的链表操作。你只要把这几个操作都能写熟练,不熟就多写几遍,我保证你之后再也不会害怕写链表代码。
这节我主要和你讲了写出正确链表代码的六个技巧。分别是理解指针或引用的含义、警惕指针丢失和内存泄漏、利用哨兵简化实现难度、重点留意边界条件处理,以及举例画图、辅助思考,还有多写多练。
我觉得,写链表代码是最考验逻辑思维能力的。因为,链表代码到处都是指针的操作、边界条件的处理,稍有不慎就容易产生Bug。链表代码写得好坏,可以看出一个人写代码是否够细心,考虑问题是否全面,思维是否缜密。所以,这也是很多面试官喜欢让人手写链表代码的原因。所以,这一节讲到的东西,你一定要自己写代码实现一下,才有效果。
今天我们讲到用哨兵来简化编码实现,你是否还能够想到其他场景,利用哨兵可以大大地简化编码难度?
欢迎留言和我分享,我会第一时间给你反馈。
今天我们来聊聊“链表(Linked list)”这个数据结构。学习链表有什么用呢?为了回答这个问题,我们先来讨论一个经典的链表应用场景,那就是LRU缓存淘汰算法。
缓存是一种提高数据读取性能的技术,在硬件设计、软件开发中都有着非常广泛的应用,比如常见的CPU缓存、数据库缓存、浏览器缓存等等。
缓存的大小有限,当缓存被用满时,哪些数据应该被清理出去,哪些数据应该被保留?这就需要缓存淘汰策略来决定。常见的策略有三种:先进先出策略FIFO(First In,First Out)、最少使用策略LFU(Least Frequently Used)、最近最少使用策略LRU(Least Recently Used)。
这些策略你不用死记,我打个比方你很容易就明白了。假如说,你买了很多本技术书,但有一天你发现,这些书太多了,太占书房空间了,你要做个大扫除,扔掉一些书籍。那这个时候,你会选择扔掉哪些书呢?对应一下,你的选择标准是不是和上面的三种策略神似呢?
好了,回到正题,我们今天的开篇问题就是:如何用链表来实现LRU缓存淘汰策略呢? 带着这个问题,我们开始今天的内容吧!
提到数组,我想你肯定不陌生,甚至还会自信地说,它很简单啊。
是的,在每一种编程语言中,基本都会有数组这种数据类型。不过,它不仅仅是一种编程语言中的数据类型,还是一种最基础的数据结构。尽管数组看起来非常基础、简单,但是我估计很多人都并没有理解这个基础数据结构的精髓。
在大部分编程语言中,数组都是从0开始编号的,但你是否下意识地想过,为什么数组要从0开始编号,而不是从1开始呢? 从1开始不是更符合人类的思维习惯吗?
你可以带着这个问题来学习接下来的内容。
上一节,我们讲了复杂度的大O表示法和几个分析技巧,还举了一些常见复杂度分析的例子,比如O(1)、O(logn)、O(n)、O(nlogn)复杂度分析。掌握了这些内容,对于复杂度分析这个知识点,你已经可以到及格线了。但是,我想你肯定不会满足于此。
今天我会继续给你讲四个复杂度分析方面的知识点,最好情况时间复杂度(best case time complexity)、最坏情况时间复杂度(worst case time complexity)、平均情况时间复杂度(average case time complexity)、均摊时间复杂度(amortized time complexity)。如果这几个概念你都能掌握,那对你来说,复杂度分析这部分内容就没什么大问题了。
我们都知道,数据结构和算法本身解决的是“快”和“省”的问题,即如何让代码运行得更快,如何让代码更省存储空间。所以,执行效率是算法一个非常重要的考量指标。那如何来衡量你编写的算法代码的执行效率呢?这里就要用到我们今天要讲的内容:时间、空间复杂度分析。
其实,只要讲到数据结构与算法,就一定离不开时间、空间复杂度分析。而且,我个人认为,复杂度分析是整个算法学习的精髓,只要掌握了它,数据结构和算法的内容基本上就掌握了一半。
复杂度分析实在太重要了,因此我准备用两节内容来讲。希望你学完这个内容之后,无论在任何场景下,面对任何代码的复杂度分析,你都能做到“庖丁解牛”般游刃有余。
你是否曾跟我一样,因为看不懂数据结构和算法,而一度怀疑是自己太笨?实际上,很多人在第一次接触这门课时,都会有这种感觉,觉得数据结构和算法很抽象,晦涩难懂,宛如天书。正是这个原因,让很多初学者对这门课望而却步。
我个人觉得,其实真正的原因是你没有找到好的学习方法,没有抓住学习的重点。实际上,数据结构和算法的东西并不多,常用的、基础的知识点更是屈指可数。只要掌握了正确的学习方法,学起来并没有看上去那么难,更不需要什么高智商、厚底子。
还记得大学里每次考前老师都要划重点吗?今天,我就给你划划我们这门课的重点,再告诉你一些我总结的学习小窍门。相信有了这些之后,你学起来就会有的放矢、事半功倍了。
你是不是觉得数据结构和算法,跟操作系统、计算机网络一样,是脱离实际工作的知识?可能除了面试,这辈子也用不着?
尽管计算机相关专业的同学在大学都学过这门课程,甚至很多培训机构也会培训这方面的知识,但是据我了解,很多程序员对数据结构和算法依旧一窍不通。还有一些人也只听说过数组、链表、快排这些最最基本的数据结构和算法,稍微复杂一点的就完全没概念。
当然,也有很多人说,自己实际工作中根本用不到数据结构和算法。所以,就算不懂这块知识,只要Java API、开发框架用得熟练,照样可以把代码写得“飞”起来。事实真的是这样吗?
今天我们就来详细聊一聊,为什么要学习数据结构和算法。
你好,我是王争,毕业于西安交通大学计算机专业。现在回想起来,本科毕业的时候,我的编程水平其实是很差的。直到读研究生的时候,一个师兄给了我一本《算法导论》,说你可以看看,对你的编程会很有帮助。
你好,我是王争。从专栏上线到今天,足足有8个月的时间了。在这8个月里,我陪你一块完成了100篇正文和11篇加餐的学习。今天,我要正式地跟你说声再见了。
你可能知道,除了《设计模式之美》这个专栏,我还有另外一个专栏《数据结构与算法之美》。两个专栏加起来已经有10万多读者了。算法专栏一直稳居极客时间的TOP 1。设计模式专栏发布时间较晚,但上升势头很好,跻身TOP 10指日可待。当然,这不是什么了不起的成绩,也并非我一个人努力的结果。我说这些当然也不是为了炫耀。
成绩虽小,算不上成功,但起码称得上“成事(做成了一件事情)”。在这篇结束语里面,我打算结合我自己写专栏的经历,跟你聊一聊对人一生有很大影响的四样东西:机遇、方向、能力、努力,我觉得它们一起决定了你是否能“成事”。