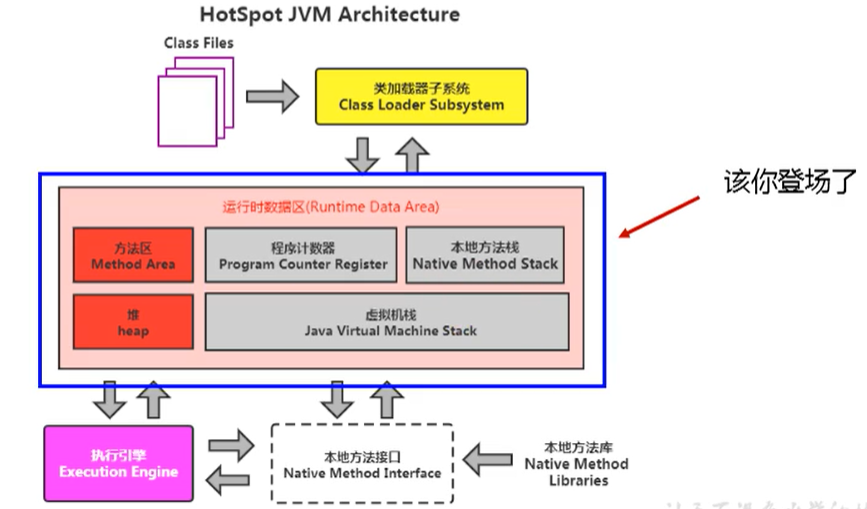
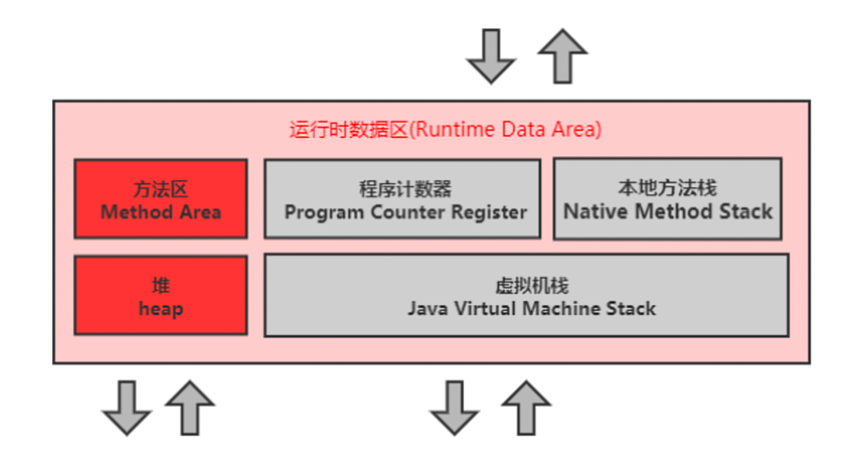
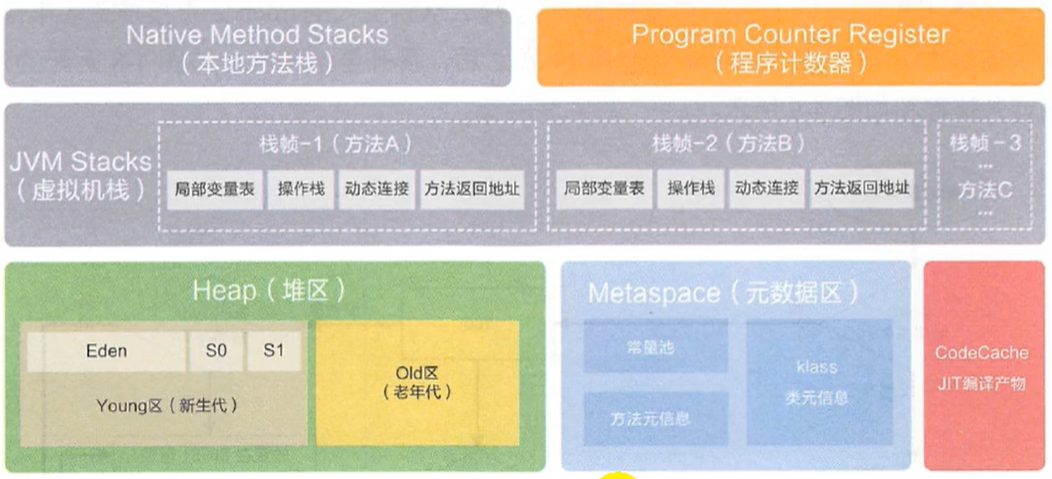
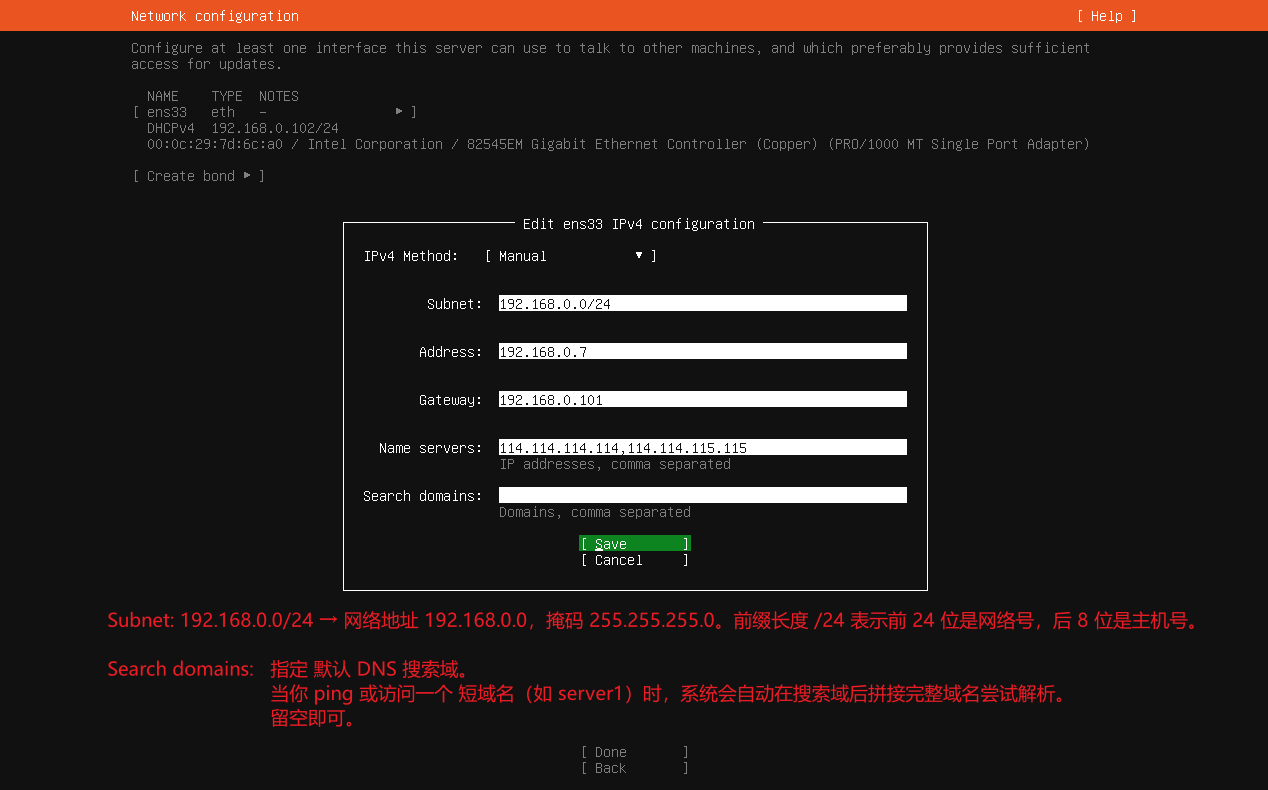
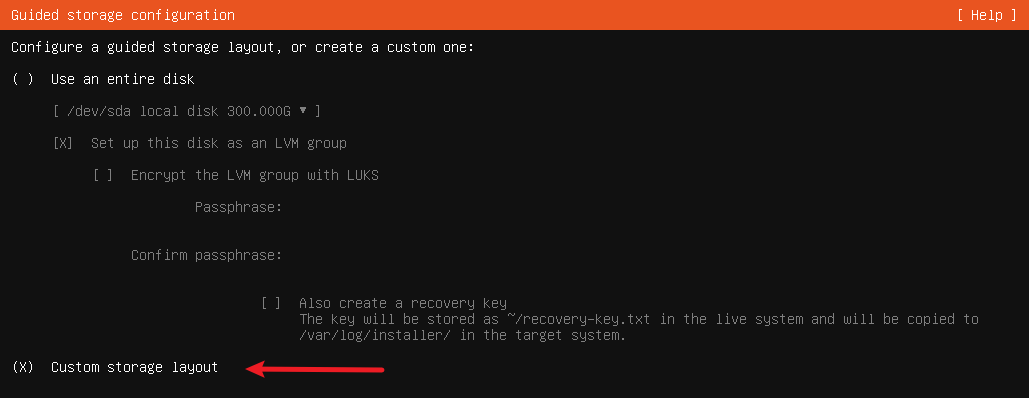
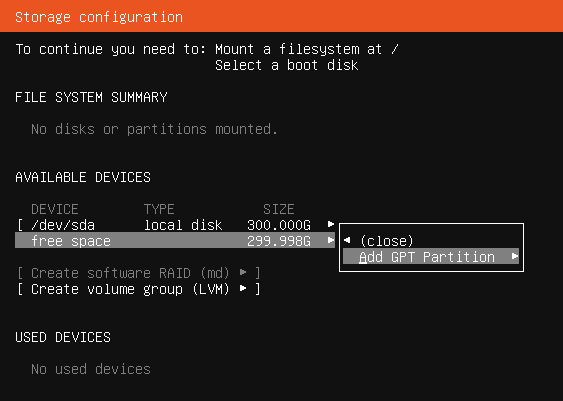
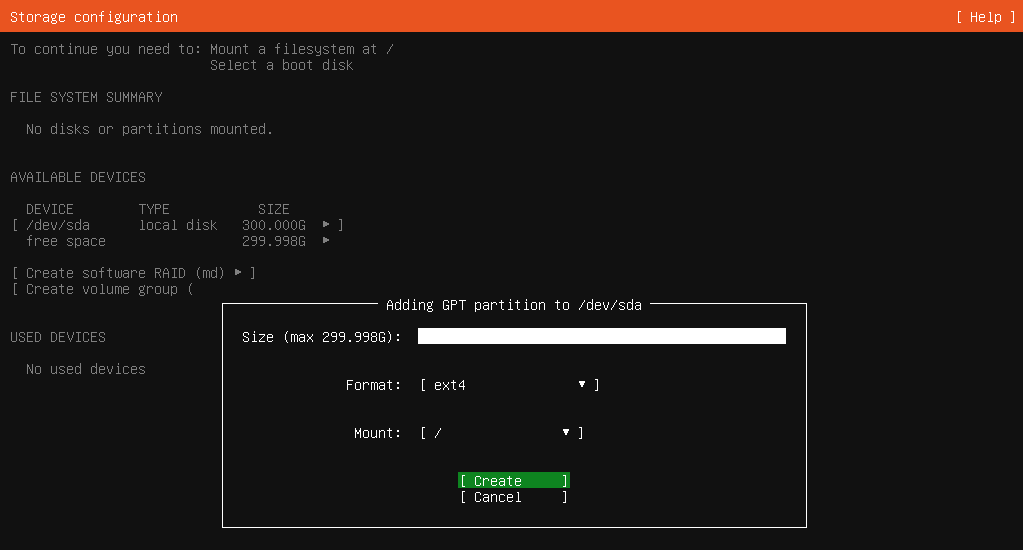
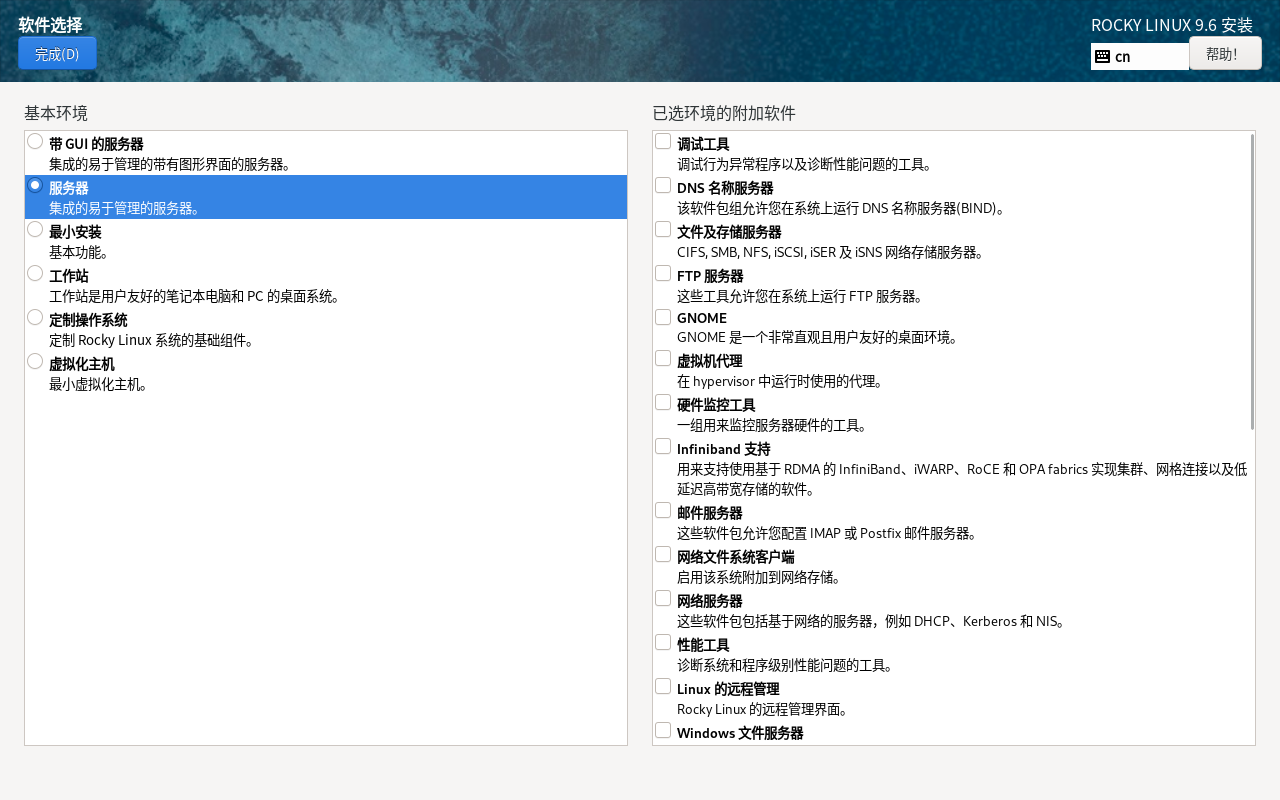
软件包管理 软件包管理系统 :dpkg 、RPM包管理员
软件包管理系统前端:APT 、YUM
软件包及依赖查询网站 Ubuntu
1 2 3 # 查看依赖 apt-cache depends gnome-core # 正向依赖(查看某个包依赖哪些包) apt-cache rdepends gnome-core # 反向依赖(查看哪些包依赖这个包)
Centos
1 2 3 # 查看依赖 dnf deplist perl # 正向依赖(查看某个包依赖哪些包) repoquery --whatrequires perl # 反向依赖(查看哪些包依赖这个包,需要安装 dnf install -y yum-utils
dpkg https://man.archlinux.org/man/dpkg
1 2 dpkg --help dpkg -L openssh-server # 显示指定软件包在系统中安装的所有文件和目录的完整路径列表。
apt-get、apt-cache、apt https://man.archlinux.org/man/apt-get
https://man.archlinux.org/man/apt-cache
https://man.archlinux.org/man/apt
简单来说:
apt-get包的安装、升级和移除 ,是传统的、面向脚本的工具。apt-cache查询本地软件包信息 (数据库),例如搜索、查看依赖。apt前端工具 ,结合了 apt-get 和 apt-cache 的最佳功能,并提供了更美观、更友好的用户体验。
三个 APT 工具的详细对比
工具
主要功能/定位
典型命令示例
特点总结
apt-get核心操作 :负责从软件源获取和安装软件包,处理实际的系统更改。传统工具 ,适合脚本编写。apt-get install <package> apt-get remove <package> apt-get update apt-get upgrade面向底层 :输出信息相对简单,没有进度条。是 APT 工具家族中历史最悠久、功能最稳定的工具。
apt-cache查询操作 :负责查询本地缓存的软件包数据库(Metadata)。它不会更改系统 或下载软件包。apt-cache search <keyword> apt-cache show <package> apt-cache depends <package>信息获取 :仅用于搜索和显示软件包信息、依赖关系等。是用户了解软件包情况的强大工具。
apt用户界面 :结合了 apt-get 和 apt-cache 的常用功能。推荐日常使用 的现代工具。apt install <package> apt remove <package> apt update apt upgrade apt search <keyword>用户友好 :提供美观的进度条 、颜色高亮和更简洁的输出。它不是要取代 apt-get,而是提供一个更好的用户界面。
rpm https://man.archlinux.org/man/rpm
1 rpm -ql openssh-server # 列出软件包中的文件。显示指定软件包在系统中安装的所有文件和目录的完整路径列表。
dnf/yum https://man.archlinux.org/man/extra/dnf/dnf4
https://man.archlinux.org/man/extra/dnf5/dnf5
dnf 是 yum 的改进和取代者。
查看系统安装了哪些软件包 查看软件包依赖了哪些包 查看软件包依赖了哪些动态库 查看软件包安装了哪些文件 查看文件来自哪个软件包 iptables 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 # REDIRECT 是 DNAT 的一种特例,用于将流量“重定向”到本机的某个端口。它会把数据包的 目标 IP 改为本机 IP,并可选地修改目标端口。方向:外部 → 本机。常用场景:本机透明代理、流量重定向/端口转发、本机端口劫持。 # DNAT 改变数据包的目标地址和目标端口,使外部访问被转发到内网主机(入站端口映射)。方向:外部 → 内部。常见场景:外部访问内网服务(端口映射)、公网访问转发到私网服务器。 # SNAT(Source NAT)用于修改数据包的源IP(和可选的源端口),使外部服务器认为请求来自指定的公网IP。方向:内部 → 外部。常见场景:内网主机访问外网时共享一个公网IP、多网卡服务器的流量伪装、NAT 路由器出站流量转换。 # 若忽略出站入栈网卡,则作用于所有网卡流量 iptables -t nat -A PREROUTING -i ens33 -p tcp --dport 8989 -j REDIRECT --to-port 22 # iptables -t nat -A PREROUTING -i ens33 -p tcp --dport 8989 -j DNAT --to-destination 192.168.0.7:22 # iptables -t nat -A POSTROUTING -o ens33 -s 192.168.0.0/24 -j SNAT --to-source 114.114.114.114 # 内网 192.168.0.0/24 子网的主机访问外网时,源地址被替换为公网IP 114.114.114.114。 # 查看 NAT 表 (nat table) 中 PREROUTING 链 的所有规则,并以数字形式显示(不反查 DNS / 服务名)。 # -t nat 指定 NAT 表(专门处理地址转换,DNAT/SNAT/REDIRECT) # -L 列出(List)该表中指定链的所有规则 # PREROUTING 指定要查看的链(chain)。PREROUTING 用于入站数据包,包到达本机前触发。 # -n 以数字方式显示 IP 和端口,不反查域名或服务名(更快更准确) # --line-numbers 给每条规则显示一个编号,便于删除或修改特定规则 iptables -t nat -L PREROUTING -n --line-numbers iptables -t nat -D PREROUTING 1 # 根据行号删除规则 iptables -t nat -D PREROUTING -i ens33 -p tcp --dport 8989 -j REDIRECT --to-port 22 # 按规则内容删除规则
流编辑器——sed Sed 是一款非常强大且常用的 流编辑器(Stream Editor) ,非常适合做批量的替换、删除、插入、打印等文本变换。
简介与工作原理
流编辑器: Sed 一次只处理一行内容。工作空间: Sed 处理文件时,会将当前处理的行读入一个临时缓冲区,称为 “模式空间” (pattern space) 。处理流程: Sed 命令会对模式空间中的内容进行处理,处理完成后,默认会将模式空间的内容输出到标准输出(屏幕)。接着清空模式空间,读取下一行,重复上述过程,直到文件末尾。非破坏性: 默认情况下,Sed 不会修改原文件内容 ,而是将结果输出到标准输出,除非使用重定向或特定的选项(如 -i)来保存更改。
sed 常用语法格式 最基本的 Sed 命令格式如下:
1 2 3 sed [选项] 'sed命令' 文件名 # 或 sed [选项] -f 脚本文件 文件名
常用选项 (Options)
选项
作用
-n静默模式(或安静模式) 。默认 Sed 会打印所有行,使用此选项后,只有被显式命令(如 p 打印命令)处理的行才会被打印。
-e允许多个 Sed 命令/脚本。例如:sed -e 'command1' -e 'command2' file
-f指定 Sed 脚本文件。例如:sed -f script.sed file
-i直接修改原文件 。这个选项非常重要,但使用时要小心,最好先备份文件。
地址(Address) Sed 命令可以指定一个地址或一个地址范围,以限制命令的作用范围。
地址格式
作用
示例
无地址 作用于文件中的所有行 。
's/old/new/'
单行号 作用于指定的行 。
'5d' (删除第 5 行)
$代表文件的最后一行 。
'$d' (删除最后一行)
/regex/作用于匹配正则表达式 的行。这是查找命令
'/error/d' (删除包含 “error” 的行)
地址范围 作用于从起始地址到结束地址 之间的行(包含边界)。
addr1,addr21,5d (删除第 1 到 5 行)
addr1,/regex/3,/end/d (删除第 3 行到第一个匹配 /end/ 的行)
/regex1/,/regex2//start/,/end/d (删除第一个匹配 /start/ 到第一个匹配 /end/ 的行)
sed 常用命令 (Commands) sed 命令通常紧跟在地址后面。
替换:s (substitute)
这是 sed 最常用、最强大的 功能。
格式: [地址]s/旧字符串/新字符串/标志示例:
s/foo/bar/:将每行中第一个 foo 替换为 bar。s/foo/bar/g:全局替换 ,将行中所有 foo 替换为 bar。s/foo/bar/p:打印发生替换的行。通常配合 -n 选项使用。s/foo/bar/w output.txt:将发生替换的行写入 output.txt 文件。s#/#\\/#g:当替换内容或目标字符串中包含 / 时,可以使用其他分隔符,例如 #。详见下文 sed 命令分隔符
删除:d (delete)
格式: [地址]d示例:
3d:删除第 3 行。1,5d:删除第 1 到 5 行。/^#/d:删除以 # 开头的行 (常用于删除注释行)。'/^$/d':删除所有空行。
打印:p (print)
格式: [地址]p用途: 配合 -n 选项 ,只打印指定的行或匹配的行。示例:
sed -n '5p' file:只打印第 5 行。sed -n '/config/p' file:只打印包含 config 关键字的行。sed -n '1,10p' file:只打印前 10 行。
追加/插入/更改:a / i / c
a (append):之后 追加新文本。
示例: '/error/a\--- An Error Occurred ---' (在包含 error 的行后面追加文本)
i (insert):之前 插入新文本。
示例: '1i\# This is a header' (在文件第一行前插入一行)
c (change):替换 匹配行或匹配范围的所有内容。
示例: '3c\Replacement Text' (用新文本替换第 3 行)
注意: a、i 和 c 命令后的文本必须换行书写(在命令行中通常用 \ 来转义换行符,或者直接跟在命令后,用 \ 隔开)。
sed 命令分隔符 分隔符(delimiter)在 sed 命令中主要用于 替换命令 和 查找命令 / ,尤其是涉及到正则表达式的部分。默认是 /。
替换命令 (s)
这是最常见的使用自定义分隔符的场景。
基本格式: s/查找模式/替换字符串/标志使用自定义分隔符的格式: sX查找模式X替换字符串X标志
这里的 X
示例命令
分隔符
场景说明
s#/var/log#/tmp/log#g#当查找或替换的内容中包含 /# 可以避免对 / 进行转义。
s@^#@ @@当查找或替换的内容中包含 #@。
查找/地址命令 (/regex/)
分隔符也可以用于定义地址 (即指定 Sed 命令作用的行范围)。当您需要查找的模式中包含默认分隔符 / 时,可以自定义分隔符。
基本格式: /正则表达式/命令使用自定义分隔符的格式: \X正则表达式X命令
示例命令
分隔符
场景说明
/\//d/ (默认)删除包含默认分隔符 / 的行,但需要转义 (\/)。
sed '\#/home/#d' file# (自定义)删除包含 /home/ 路径的行,无需转义路径中的 /,但需在开头用 \ 声明自定义分隔符。
进阶示例 组合多个命令 使用 -e 选项或分号 ;:
1 2 3 4 # 删除空行,并将所有的 'old' 替换为 'new' sed -e '/^$/d' -e 's/old/new/g' file.txt # 或者使用分号 sed '/^$/d ; s/old/new/g' file.txt
括号分组和后向引用 在替换命令 s 中,可以使用括号 () 对匹配模式的一部分进行分组,并在替换字符串中用 \1, \2, … 进行引用。注意: 括号需要用 \ 进行转义,即 \( 和 \)。
1 2 3 # 假设一行内容是 "apple banana" # 将其转换为 "banana apple" echo "apple banana" | sed 's/\(apple\) \(banana\)/\2 \1/'
\(apple\) 匹配并捕获第一个单词,标记为 \1。\(banana\) 匹配并捕获第二个单词,标记为 \2。替换字符串 \2 \1 将它们的位置交换。
文件定位 whereis命令 、 locate/slocate命令 、 find命令 、 which命令 、 rpm命令
以 nginx 安装目录为例:
1 2 3 4 5 6 7 8 9 10 11 12 [root@localhost ~]# whereis nginx [root@localhost ~]# whereis -b nginx # 定位指令的二进制程序、源代码文件和man手册页等相关文件的路径 [root@localhost ~]# locate nginx # 搜索一个数据库/var/lib/locatedb,查找目录与文件,但查不到最新的变动,为避免这种情况应先使用updatedb命令 [root@localhost ~]# find / | grep nginx # 在指定目录下查找子目录与文件 [root@localhost ~]# which nginx # 查找并显示给定命令(可执行程序)的绝对路径。查看某个系统命令是否存在并显示命令位置。 # rpm命令是RPM软件包的管理工具 [root@localhost ~]# rpm -qa | grep nginx # 列出安装过的软件包,且包含字符串nginx [root@localhost ~]# rpm -q nginx # 获取nginx软件包的全名 [root@localhost ~]# rpm -ql nginx # rpm包中文件的安装位置 [root@localhost ~]# rpm -qal | grep nginx
网络状态 1 2 3 4 5 6 7 8 9 10 11 12 13 14 yum install -y lsof lsof -i:8080 # 查看端口是否被占用,有列头,推荐使用 yum install -y net-tools netstat -ntlp # 查看当前所有tcp端口 netstat -nulp # 查看当前所有udp端口 netstat -an | grep 80 # 查看所有包含80的端口使用情况 netstat -ntulp | grep 80 # 查看所有包含80的端口使用情况,包括PID(进程ID)、进程名。 netstat -tunlp | grep 80 # 查看所有包含80的端口使用情况,包括PID(进程ID)、进程名。 # -t : 指明显示TCP端口 # -u : 指明显示UDP端口 # -l : 仅显示监听套接字(所谓套接字就是使应用程序能够读写与收发通讯协议(protocol)与资料的程序) # -p : 显示进程标识符和程序名称,每一个套接字/端口都属于一个程序。 # -n : 不进行DNS轮询,显示IP(可以加速操作)
进程状态 Linux ps 命令 - 菜鸟
1 2 3 4 5 6 7 8 [root@localhost ~]# ps aux [root@localhost ~]# ps aux | grep nginx [root@localhost ~]# ps -f [root@localhost ~]# ps -ef [root@localhost ~]# ps -ef | grep nginx ps axw -o pid,ppid,user,%cpu,vsz,wchan,command | egrep '(nginx|PID)'
输出头(标题) Linux head 命令 - 菜鸟
在使用Linux命令时,如果命令中有管道 | ,则输出的信息中,头(标题)信息丢失,要想看每一列代表什么意思很不方便。
例如 ps auxw:
1 2 3 4 5 6 7 8 9 10 11 $ ps axuw USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND root 1 0.0 0.3 193984 6556 ? Ss 08:51 0:03 /usr/lib/systemd/systemd --switched-root --system --deserialize 22 root 2 0.0 0.0 0 0 ? S 08:51 0:00 [kthreadd] root 4 0.0 0.0 0 0 ? S< 08:51 0:00 [kworker/0:0H] root 5 0.0 0.0 0 0 ? S 08:51 0:00 [kworker/u128:0] root 6 0.0 0.0 0 0 ? S 08:51 0:00 [ksoftirqd/0] root 7 0.0 0.0 0 0 ? S 08:51 0:01 [migration/0] root 8 0.0 0.0 0 0 ? S 08:51 0:00 [rcu_bh] root 9 0.0 0.0 0 0 ? S 08:51 0:03 [rcu_sched] root 10 0.0 0.0 0 0 ? S< 08:51 0:00 [lru-add-drain]
再加上管道符后
1 2 3 4 5 $ ps axuw | grep redis esuser 2636 0.0 0.0 192 4 ? Ss 08:52 0:00 /usr/bin/dumb-init -- /redis-commander/docker/entrypoint.sh polkitd 2654 0.2 0.4 52956 9020 ? Ssl 08:52 0:09 redis-server *:6379 esuser 2810 0.0 1.9 272292 36548 ? Ssl 08:52 0:01 /usr/bin/node ./bin/redis-commander root 39925 0.0 0.0 112824 980 pts/0 S+ 10:05 0:00 grep --color=auto redis
可以看到头(标题)已经丢失。
一个简单的办法,通过 2 条命令叠加
1 2 3 4 5 6 $ ps axuw | head -1;ps axuw | grep redis USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND esuser 2636 0.0 0.0 192 4 ? Ss 08:52 0:00 /usr/bin/dumb-init -- /redis-commander/docker/entrypoint.sh polkitd 2654 0.2 0.4 52956 9020 ? Ssl 08:52 0:09 redis-server *:6379 esuser 2810 0.0 1.9 272292 36548 ? Ssl 08:52 0:01 /usr/bin/node ./bin/redis-commander root 40905 0.0 0.0 112824 984 pts/0 S+ 10:07 0:00 grep --color=auto redis
也就是先用命令本身加 | head -1 取到头(标题),然后再使用该命令输出内容,两者叠加输出即得到所要结果。
排序——sort Linux sort命令 - 菜鸟
排序命令——sort
按列排序,数字大的在前:
1 2 3 4 5 6 7 8 $ ps auxw | sort -rnk 2 root 44271 0.0 0.0 126840 928 pts/0 S+ 10:14 0:00 sort -rnk 2 root 44270 0.0 0.0 155448 1868 pts/0 R+ 10:14 0:00 ps auxw root 44269 0.0 0.0 108052 612 ? S 10:14 0:00 sleep 1 201 44263 0.0 0.0 1560 248 ? SN 10:14 0:00 sleep 1 201 33288 0.0 0.0 2412 1400 ? SN 09:52 0:01 bash /usr/libexec/netdata/plugins.d/tc-qos-helper.sh 1 root 8204 0.0 0.0 0 0 ? S< 09:02 0:00 [kworker/11:1H] ......
该例子,将第 2 列进行排序,最大的数排前面。
若只想看前10条的内容:
1 $ ps auxw | sort -rnk 2 | head -10
将实际内存消耗最大的10个进程显示出来:
1 2 $ ps auxw | head -1; ps auxw | sort -rnk 6 | head -10 $ ps auxw --sort =-rss | head -11
统计——wc 统计命令——wc
切分——cut 切分命令——cut
去重——uniq 去重命令——uniq
强大的文本分析命令——awk awk 命令 - 菜鸟 强大的文本分析命令——awk
1 ps -ef | grep mar-service.jar:60002 | grep -v grep | awk '{ print }'
服务管理 systemctl命令 :是系统服务管理器指令,它实际上将 service 和 chkconfig 这两个命令组合到一起。
1 2 3 4 5 6 7 8 9 10 11 # 查看所有可用的单元文件 [root@localhost ~]# systemctl list-unit-files | grep '' # 查看所有已安装服务 [root@localhost ~]# systemctl list-unit-files --type=service | grep '' # 输出激活的unit,下面两个命令等效 [root@localhost ~]# systemctl | grep '' [root@localhost ~]# systemctl list-units | grep '' # 输出激活的类型为service的unit [root@localhost ~]# systemctl list-units --type=service | grep '' [root@localhost ~]# systemctl list-units --type=service | grep nginx
vim 中查找和替换 vi / vim 键位图: https://www.runoob.com/linux/linux-vim.html
https://harttle.land/2016/08/08/vim-search-in-file.html
https://blog.csdn.net/ballack_linux/article/details/53187283
清空历史命令 history命令
.bash_history 默认可记录 500 条历史命令。
只有在正常退出当前 shell 时,在当前 shell 中运行的命令才会保存至 .bash_history 文件中。
1 2 3 [root@localhost ~]# history 10 # 显示最近使用的10条历史命令 [root@localhost ~]# history -c # 清空当前shell历史命令记录 [root@localhost ~]# rm -rf ~/.bash_history # 删除'.bash_history'文件
若想在每次登录后都清空历史记录,可以在登录后 或登出前 执行 rm -rf ~/.bash_history 即可。
Wget 和 cURL 百科: Wget 、 wget命令 、 cURL 、 curl命令
curl 与 wget
wget命令 用来从指定的URL下载文件。
curl命令 是一个利用URL规则在命令行下工作的文件传输工具。curl URL 默认将下载文件输出到stdout,将进度信息输出到stderr(默认也是终端),可以使用 -O(使用原文件名)或 -o(指定输出文件名)指定输出位置。curl支持更多的协议,还支持cookies、认证、限速、文件大小等特征。
1 2 [root@localhost ~]# wget -c URL [root@localhost ~]# curl URL -O --progress
删除文件/文件夹 1 2 3 4 rm -rf # 文件或文件夹名 # -i 删除前逐一询问确认。 # -f 即使原档案属性设为唯读,亦直接删除,无需逐一确认。 # -r 将目录及以下之档案亦逐一删除。
解压缩 tar 1 2 3 # 解压 tar -zxvf jdk-7u80-linux-i586.tar.gz tar -zxvf /mnt/hgfs/SharedFolders/openjdk-11+28_linux-x64_bin.tar.gz -C /data/
zip 1 2 3 4 5 6 7 8 9 10 11 12 # 安装zip、unzip应用 yum install zip unzip # Centos apt install zip unzip # Ubuntu # 解压 unzip /mnt/hgfs/SharedFolders/linuxx64_12201_database.zip -d /data # 将 /home/html/ 这个目录下所有文件和文件夹打包为当前目录下的 html.zip zip -q -r html.zip /home/html # 如果在我们在 /home/html 目录下,可以执行该命令 zip -q -r html.zip * # 从压缩文件 cp.zip 中删除文件 a.c zip -dv cp.zip a.c
7z Linux有问必答:Linux 中如何安装 7zip
支持 7Z,ZIP,Zip64,TAR,RAR,CAB,ARJ,GZIP,BZIP2,CPIO,RPM,ISO,DEB 压缩文件格式 。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 # 安装 $ yum install p7zip p7zip-plugins $ apt install p7zip-full p7zip-rar # 将01.jpg和02.png压缩成一个7z包 $ 7z a pkg.7z 01.jpg 02.png # 将所有的.jpg文件压缩成一个7z包 $ 7z a pkg.7z *.jpg # 将文件夹folder压缩成一个7z包 $ 7z a pkg.7z folder # 将pkg.7z中的所有文件解压出来,e是解压到当前路径 $ 7z e pkg.7z # 将pkg.7z中的所有文件解压出来,x是解压到压缩包命名的目录下 $ 7z x pkg.7z
nohup 相关链接: 百科 、 Linux nohup 命令 - 菜鸟 、 shell中的特殊字符大全
nohup命令 可以将程序以忽略挂起信号的方式运行起来,被运行的程序的输出信息将不会显示到终端。 如果不将 nohup 命令的输出重定向,输出将追加到当前目录的 nohup.out 文件中。
nohup command >/dev/null 2>&1 & 意思就是,将command保持在后台运行,并且将输出的日志忽略。
1 2 nohup java -jar -Dserver.port=9088 gateway.jar >/dev/null 2>&1 &
备份脚本 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 # !/bin/bash # 日志文件的存放路径。$0 代表当前脚本的路径,dirname "$0 " 会提取出脚本所在的目录。这意味着该日志文件将始终生成在与该脚本相同的目录下。 LOG_FILE=$(dirname "$0")/backup.log # 日志记录函数。$1 代表传入的参数。tee 指令会从标准输入读取数据,将其内容传输到标准输出(屏幕),同时保存成文件,-a (append):追加到现有文件的末尾,而不是覆盖它。 log() { echo "[$(date '+%Y-%m-%d %H:%M:%S')] $1" | tee -a "$LOG_FILE" } # 核心备份函数 backup() { local src="$1" local dest="$2" log "Starting backup: $src -> $dest" if rsync -avz --progress --exclude='*.log' "$src" "$dest"; then # 如果 rsync 成功执行(返回码为 0),则记录成功日志。 log "Backup succeeded: $src -> $dest" else # 如果失败,记录错误日志,并执行 exit 1。这非常重要,意味着只要有一个目录备份失败,整个脚本就会立刻终止,不会继续尝试备份后面的目录。 log "ERROR: Backup failed: $src -> $dest" exit 1 fi } # 备份的目标地址,需要提前配置SSH信任 TARGET="192.168.0.79:/vg/backup/cleansource" # --------------------------- 执行备份任务 # 备份SCA Web backup "/ssd1" "$TARGET" # 备份Minio backup "/vg/cleansource/minio" "$TARGET" # 备份知识库 backup "/vg/cleansource/kb" "$TARGET" # 备份数据库正确的做法是:1、先使用数据库自带的导出工具(如 mysqldump 或 pg_dump)生成一个逻辑备份文件;2、然后再用 rsync 同步备份文件。 log "All backups completed successfully."